# 🦐皮项目总结
# zone电子围栏
难点模块:undo、redo,精准的吸附、贴边的处理、边界的切割、split、merge、绘制
整体结构 -- 主要功能模块与初始化
DrawingManger:管理绘制、编辑、删除一个或多个zone多边形的状态、方法
EventManager:管理所有地图、及地图中图形的监听事件
ActionLogManager: 管理所有Zone绘制过程中的操作记录Log,及相关数据的统一处理
UndoRedoManager:管理UndoRedo操作涉及的状态、方法
# 蒙层与可编辑区域
解决方案:
- 限制地图的最小缩放级别、避免用户看到蒙层边缘
- 监听地图的
dragend事件,将可视区域控制在画Zone的有效区域附近 - 利用了
GeoJSON中有孔的Polygon作为蒙层,孔的区域作为画Zone的有效区域
TIP
- 有孔
polygon:
- 内部有多边形孔的
Polygon多边形,第二个数组所描述的就是多边形内孔 - 作为孔的多边形,孔各点的坐标需按逆时针顺序,如何判断是否为顺时针方法turf.js (opens new window)
- 使用一个比东南亚还要大的
polygongeojson数据
{
"type": "Polygon",
"coordinates": [
[
[
69.2578125,
-43.19716728250127
],
[
179.421875,
-43.19716728250127
],
[
179.421875,
29.84064389983441
],
[
69.2578125,
29.84064389983441
],
[
69.2578125,
-43.19716728250127
]
]
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 绘图
使用google map提供的Drawing Tools封装了一个图形绘制的整体过程,只暴露了绘制完成的事件。而电子围栏模块的需求中,对于图形绘制的过程中,每次的落点都有交互和处理的逻辑,所以没法应用
# 一些细节
- 如何判断
polygon不自相交 (turf/kinks (opens new window)),zone交给后台切割返回,unit提示自相交 - 绘制过程
polygon互相相交会自动切割,zone中交给后台处理,unit中sdk处理 - 绘制时会自动进行多边形吸附,支持业务传入
snap进行配置 - 绘制完成后计算面积 turf/area (opens new window),
zone让后台处理 - 拖动多边形点可以更新多边形,之前使用
google map可以删掉多边形上的点 - 合并多边形可以看看 turf/union (opens new window),业务使用接口来处理
split分割多边形undo, redo
# 可以删除线上的点,更新多边形
# Split zone
对比引线只能在边上,跟超出zone边界的两种交互的实现
- 遍历zone图形所有点,以split线的点为分界线,将两侧点分别加入到两个新的zone图形中,并通过坐标点旋转以避免多边形出现孔的情况。
- 使用
new google.maps.Polyline创建一条分割线
# Add Zone
# 初始
初始化Polyline和Polygon,绘制过程中,更新Zone的Polyline以及Polygon的数据,渲染更新的Polyline到地图。绘制完成时,渲染Zone的Polygon到地图。
各初始化的任务:
- 初始化DrawingManager,创建新的Zone轨迹的PolyLine和Zone图形的Polygon对象
- 初始化UndoRedoManager,准备后续记录用户的绘图操作
- 初始化各个Add过程中的交互功能的事件注册。包括: a. 落点时,更新Zone的轨迹线Polyline b. 鼠标移动时,渲染引线,提示框 c. 鼠标移动时,寻找,计算和显示自动吸附点 d. 鼠标移入移出有效区域时的处理 e. 鼠标双击时,完成Zone的闭合和绘制 f. drag/drop现有的点时,更新该点的位置 g. 右键点击现有的点时,提供可以删除该点的选项
# 边的自动吸附
- add操作过程中,始终有引线跟随,当引线接近绘制区域边界、或是其他zone的边界时,会自动吸附到该边上。
- 通过Map API提供的
isLocationOnEdge方法 - 但是这个无法保证精确度,提供点buffer
- 找到buffer内的点后,通过几何计算,找到临近的边上距离目标点最新的点(涉及墨卡托坐标系转换)
# 切边处理
绘制完成后提交数据,后端对提交的polygon数据与服务范围边界进行计算,去掉边界外的部分
# merge zone
现有方案交给后台处理
# webpack 构建优化
- 开发构建时会编译所有页面,但是开发可能只关注若干页面
- 缺少编译缓存
- 单线程
TIP
webpack从v4升级到v5,由于升级了 webpack,webpack-cli,plugin 以及 loader 的版本,因此,可能会出现新的错误或警告。在编译过程中请注意是否有弃用警告。
你可以通过如下方式调用 webpack 来获取堆栈信息中的弃用警告,从而找出是哪个 plugin 或 loader 造成的。
node --trace-deprecation node_modules/webpack/bin/webpack.js
# thread-loader插件,多线程构建
线程池线程数量,现代计算机一般有多个核,主线程占一个核,剩下的核我们把大约一半分给 vue 模块,剩余分给 js 模块,
假设计算机核数为 cpuCount ,
- 在
vue模块配置中,workersForVue = Math.max(1, Math.floor((cpuCount - 1)/2 - 1)) - 在
js模块配置中,workersForJs = Math.max(1, cpuCount - workersForVue)
# cache-loader,增加编译缓存
安装
cache-loader,在开发环境配置里的vue-loader和babel-loader加上缓存相关配置项
配置项
| loader | options |
|---|---|
| vue-loader | { cacheDirectory: node_modules/.cache-${userName}/vue-loader, cacheIdentifier: getCacheIdentifier(envIndentifier, ['cache-loader', 'vue-loader']), } |
| babel-loader | { cacheDirectory: node_modules/.cache-${userName}/babel-loader, cacheIdentifier: getCacheIdentifier(envIndentifier, ['cache-loader', 'babel-loader', 'acribus', 'acribus-core']), } |
TIP
userName为当前用户名,开发过程可能使用sudo进行构建,不同用户使用不同缓存目录,sudo下userName为root。
const os = require('os');
const userName = os.userInfo().username;
2
3
getCacheIdentifier是生成缓存标识(cacheIdentifier)的函数,缓存标识用于与单个文件的修改时间一起生成该文件的缓存标识。 代码参考:create-react-app/packages/react-dev-utils (opens new window)envIndentifier为环境变量标识,当环境变量变更的时候,缓存应该失效,所以缓存标识与环境变量相关。
const envIndentifier = `${FTE}-${ENV}-${mode}` // FTE 环境变量 表示当前构建环境,test/uat/staging...,ENV 环境变量表示当前哪个市场,id/th/my/ph/tw/br... mode构建模式(development)
# 升级到 webpack5,利用 webpack5的模块联邦 (module federation)功能,进行模块拆分,让模块独立编译和维护
- 提升开发体验
- 满足部分业务独立维护和发布的需求
- 降低项目复杂度,减少迭代成本
TIP
- 共享NPM包设计
由于每个子应用都有自己的
package.json,包含自己用到的npm包,不同的子应用可能会用到同一个包,例如vue,vue-router和lodash等,在子应用开发过程中,可能会升级某个包,导致不同的子应用该包的版本不一致,如果那个包是支持多实例或者没有全局副作用的,多版本是没有问题的,否则就会产生冲突。
如何避免冲突:
- 把共享的
npm包放主应用,升级时通过修改主应用来完成升级,把主应用package.json里列出来的所有依赖都配置成共享 - 通过配置,确保共享的
npm包在运行时只会存在一个版本webpack module federation里的singleton配置可以让某个共享包在运行时只会加载一个,并且是最高版本的那个。(版本一样,按package.json内的name字段来比较) - 在运行时检查
npm包版本,确保主应用里的版本比子应用里的版本高,和提示被不同子应用用到但是没有共享的包
- 加载子模块应该不阻塞主应用的启动,子模块的代码应该通过异步的方式加载。即通过手动加入标签的方式,异步加载
remoteEntry.js
# webpack打包优化
# fms打包效率优化
- 分析包体积:打包时间112s,大小20.81MB
- 部分包体积大的引入
cdn
TIP
- 干掉
element-ui,包大小变为20.23MB vue,vuex,vue-routervue全家桶接入cdn后,大小为20.12MBecharts接入cdn后,体积变为19.72MBxlsx.js:升级版本,由0.17.x升级到0.18.x(支持tree-shaking`)。全量加载改成按需加载。打包时间变为80.7s,大小19.23MB- 翻译资源JSON文件改成使用 tsp
- acribus改成异步加载
- 通过
SplitChunk.maxSize将超过制定大小的包再进行拆分,配合http2多路复用特性效果更好 - 因为acribus及代码循环历史原因,没有使用
esbuild-loader代替babel-loader,只使用ESBuildMinifyPlugin压缩js/css,提升不少速度
# 提升打包效率
- 使用
speed-measure-webpack-plugin分析启动耗时 - 引入懒编译
lazyCompilation,只针对views文件进行懒编译。(跳转路由时触发增量编译)
引入
webpack的懒编译,首次启动的时间(55.48s)降为之前的47%左右(现在26.64s),提升了53%的效率。首次进入页面耗(打开本地spx)时再次编译耗时1.8s,跳转路由再次触发编译耗费2.64s的时间。整体的效果相比优化前有明显的提升。但是由于每次进入新的页面都会触发编译,导致体验感稍微降低。
- 减少不必要的压缩,启动时间降为22.001s,减少4.63s
optimization: {
minimize: false,
}
2
3
- 增加缓存方案,首次启动性能有所下降,首次启动时间上升到27.43s,二次启动启动时间为24.19s
cache: {
type: 'filesystem'
}
2
3
# fms LCP优化专项
LCP(largest contentful paint),从7s到3s。从devtools -> performance insights可以看到
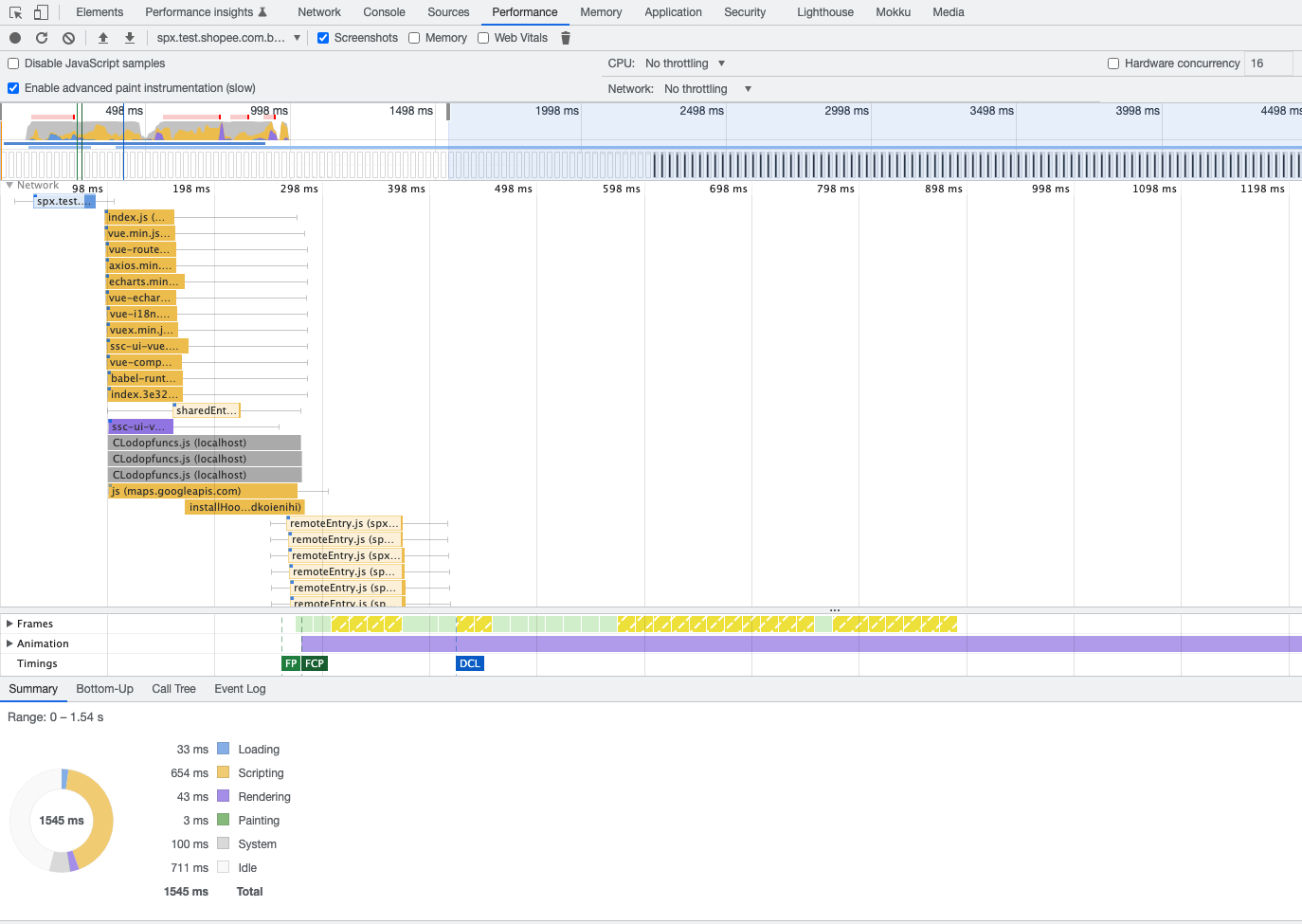
# 优化措施
开发模式下
- 把所有必须的数据请求到
index.html页面执行。
- 子应用
remoteEntry添加到preload。前置到html中加载 - ajax请求 放到 index.html
懒加载 acribus shcema
fms-admin使用vue基础组件库CDN
首屏加载存在一个阶段,并行加载了大量
js chunk,而其中属于vue基础组件库的chunk数量较多。此外,在主应用和子应用中也存在重复引入相同组件的情况。通过将vue基础组件库部署到cdn,在fms-admin统一使用cdn的组件库资源,则可以缓解这些问题。
- 对各初始化API增加IndexDB的缓存
cdn缓存时间从十分钟改为7天
TIP
优化前主应用chunk 数量121个,子应用部分58个。优化后主应用chunk数83个,子应用46个。
# Admin微前端加载优化
# 背景
使用 Module federation 拆分之后,由于需要异步加载子应用远程入口(remote entry)和资源,页面 LCP 可能会增大,过程大概如下:
- 应用入口被加载
- 子应用的
remote entry并行加载 - 子应用资源并行加载
- 页面显示
这几个步骤是串行的,会阻塞页面的渲染。要想减少 LCP,主要有两方面的优化:
- 加快
remote entry加载 - 减少子应用资源的加载和注册对渲染的阻塞
# 对remoteEntry的缓存控制
- 不缓存
通常来说,
remote entry是不能使用强缓存的,因为在子应用发布后其他应用需要加载到最新的remote entry才能正确的使用最新发布的子应用的功能。 所以在一开始的时候我们通过在加载remote entry的时候在url上添加时间戳来保证每次加载到的remote entry都是最新的,这种方式存在两个问题:
- 没有缓存,加载时间长
- 当某个应用被多个其他应用依赖时,由于带时间戳的
URL不同,会导致一个remote entry被加载多次(多个运行时)从而引起问题
- 协商缓存 +
preload为了解决面提到的问题,我们把remote entry改成了协商缓存。使用协商缓存之后,每个子应用的remote entry的加载URL都是固定的,于是我们又增加了 预加载(preload),对减少LCP有一定的效果。
# 子应用懒加载
用户进入页面的时候,那个页面往往只属于一个子应用,也就是只有那个子应用是必须的,其他的子应用的注册不应该阻塞页面渲染,所以可以做成懒注册。
子应用资源拆分两部分:
initModule:包含页面初始渲染必要的资源,例如路由信息lazyModule:包含页面初始渲染不必要的资源,例如storeinitModule的加载会阻塞渲染流程,而lazyModule的加载则不会,它会跟initModule并行加载。lazyModule只有在打开子应用的页面时才会被注册。
- 模块注册时,如果存在
lazyModule,将会创建一个beforeEnter函数。将该函数添加到initModule里的每个route里
# 按市场需要加载子应用
有一些子应用只在部分地区开放,为了节省资源和提升速度,其他地区没有必要加载,所以我们需要支持根据地区来按需加载子应用。
由于我们是通过内置的 import 函数来引入子应用模块的,它会在编译时根据 module federation 的 remotes 来觉得这次编译有哪些子应用的 remoteEntry 需要被加载。另外,我们所有地区用的都是同一份代码,所以代码里面必然存在所有子应用的 import 语句,这样的话,编译出来的代码将包含所有加载 remoteEntry 的代码。
因此,我们不能使用编译时方案,并且我们需要自定义加载 remoteEntry 的方法,这样才可以避免加载不需要的子应用 remoteEntry。
# 翻译工具(顺带看i18n开源原理)
# 原理细说
blueimp-md5生成32位 最终使用slice(8, 24)截取了16位来作为key
TIP
key由 Project,NameSpace,Label加_拼接组成,所有空格替换为_
- 缩小平均长度:根据实际数据统计,生成的规范 label 平均长度在 25 以上,而且存在个别超长长度会影响数据边界
- 保证唯一性:采用
md5算法是为了保证唯一性,避免冲突 - 易于区分:工具生成的
key统一为 16 位MD5,特征比较明显,便于后续工具分析和区分
- 项目名_key的模块名称(默认other)_label(需要翻译的文案)用来生成key。模块名称是指可能同一个文案label在不同模块下翻译含义可能有所不同